
测试与调试
添加测试需要的依赖:
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-test</artifactId>
<version>3.1.4.RELEASE</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
在命令式编程中,调试通常都是非常直观的:直接看栈调用能定位到问题位置,是否自己代码实现有问题,还是调用的第三方库报错等等。
响应式的异步代码测试和调试起来会比命令式编程麻烦的多,不过我们先了解一个基本的单元测试工具 ——
StepVerifier。
当测试时关注于每一个数据元素的时候,就非常适合 StepVerifier 的使用场景:下一个期望的数据或信号是什么?是否想要某一个特别的值等等。
以发出 1-6 的 Flux 为例:
private Flux<Integer> generateFlux() {
return Flux.just(1, 2, 3, 4, 5, 6);
}
@Test
public void testVerify() {
StepVerifier.create(generateFlux())
.expectNext(1, 2, 3, 4, 5, 6)
.expectComplete()
.verify();
}
expectNext用于测试下一个期望的数据元素。expectComplete用于测试下一个元素是否为完成信号。
以一个错误的数据流为例:
private Mono<Void> generateError() {
return Mono.error(new RuntimeException("some error"));
}
@Test
public void testVerify() {
StepVerifier.create(generateError())
.expectErrorMessage("some error")
.verify();
}
expectErrorMessage用于测试是否有指定信息的异常信号。
对于终止事件,相应的期望方法(比如 expectComplete()、expectError(),及其所有的变体方法)使用之后就不能再继续增加别的期望方法,最后只能对 StepVerifier 触发校验(verify())。
再看一个例子:
private Mono<Integer> getMonoWithException() {
return Flux.range(1, 5)
.map(i -> i * i)
.filter(i -> (i % 2) == 0)
.single(); // 1
}
single方法必须且只能接收一个元素,没有和多了都会导致异常。
@Test
public void testBug() {
getMonoWithException()
.subscribe();
}
运行用例,异常信息:

能看到异常内容大部分都是 Reactor 库内部的调用,上边 stack trace 的问题还是出自 .subcribe() 那一行。
在命令式编程的方式中比较容易使用 IDEA 的工具进行调试,但在异步编程方式下,就不太好使了。所以还是得使用响应式编程库本身提供的调试工具。
开启调试模式
Hooks.onOperatorDebug();
调试模式能在抛出异常时打印一些有用的信息,把这一行加上:
@Test
public void testBug() {
Hooks.onOperatorDebug();
getMonoWithException()
.subscribe();
}
这时再运行,增加了以下内容:
Suppressed: reactor.core.publisher.FluxOnAssembly$OnAssemblyException:
Assembly trace from producer [reactor.core.publisher.MonoSingle] :
reactor.core.publisher.Flux.single(Flux.java:7989)
com.opoa.WebfluxTest.getMonoWithException(WebfluxTest.java:21)
Error has been observed at the following site(s):
*__Flux.single ⇢ at com.opoa.WebfluxTest.getMonoWithException(WebfluxTest.java:21)
这样就能定位到问题根源。
Hooks.onOperatorDebug() 是一种全局性的 Hook,会影响到应用中所有的操作符,所以带来的性能成本也是比较大的。如果我们大概知道问题可能在哪,而对整个应用开启调试模式,也容易被茫茫多的调试信息淹没。这时,我们需要一种更精准的定位方式。
使用 checkpoint() 定位
如果我们知道问题出在哪个链上,就可以针对这个链使用 checkpoint() 进行问题定位。
checkpoint() 操作符就像一个 Hook,但它的作用范围仅限于这个链上。
@Test
public void testBug() {
getMonoWithException()
.checkpoint()
.subscribe();
}
出现异常时仍然可以打印出调试信息:
Suppressed: reactor.core.publisher.FluxOnAssembly$OnAssemblyException:
Assembly trace from producer [reactor.core.publisher.MonoSingle] :
reactor.core.publisher.Mono.checkpoint(Mono.java:2177)
com.opoa.WebfluxTest.testBug(WebfluxTest.java:27)
Error has been observed at the following site(s):
*__checkpoint() ⇢ at com.opoa.WebfluxTest.testBug(WebfluxTest.java:27)
调度器与线程模型
在以往的多线程开放场景中,使用 Executors 可以创建四种线程池:
newCachedThreadPool创建一个弹性大小缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收线程,则创建线程;newFixedThreadPool创建一个大小固定的线程池,可控制线程最大并发数,超出的线程会在队列中等待;newScheduledThreadPool创建一个大小固定的线程池,支持定时及周期性的任务执行;newSingleThreadExecutor创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序执行。
Reactor 让线程管理和任务调度更加简单 —— 调度器(Scheduler) 帮我们搞定这件事。
Scheduler 是一个拥有多个实现类的抽象接口。Schedulers 类提供的静态方法可以搭建以下几种线程执行环境:
- 当前线程(
Schedulers.immediate()); - 可重用的单线程(
Schedulers.single())。这个方法对所有调用者都提供同一个线程使用,直到该调度器被废弃。如果想使用独占的线程,请使用Schedulers.newSingle(); - 弹性线程池(
Schedulers.elastic())。它根据需要创建一个线程池,重用空闲线程。线程如果空闲时间过长(默认为 60s)就会被销毁。对于 I/O 阻塞的场景比较适用。Schedulers.elastic()能够方便地给一个阻塞的任务分配它自己的线程,而不会妨碍其他任务和资源。 - 固定大小线程池(
Schedulers.parallel()),所创建的线程池的大小与 CPU 个数相同。
Schedulers 类已经预先创建了几种常用的线程池:使用 single()、elastic() 和 parallel() 方法可以分别使用内置的单线程、弹性线程池和固定大小线程池。如果想创建新的线程池,可以使用 newSingle()、newElastic() 和 newParallel() 方法。
Executors 提供的几种线程池在 Reactor 中都支持:
Schedulers.single()和Schedulers.newSingle()对应Executors.newSingleThreadExecutor();Schedulers.elastic()和Schedulers.newElastic()对应Executors.newCachedThreadPool();Schedulers.parallel()和Schedulers.newParallel()对应Executors.newFixedThreadPool();
包装一个同步阻塞的调用
很多时候,信息源是同步和阻塞。在 Reactor 中,我们可以用以下方式处理:
Mono.fromCallable(() -> { // 1
return /* make a remote synchronous call */ // 2
})
.subscribeOn(Schedulers.boundedElastic()); // 3
- 使用
fromCallable生成一个Mono; - 返回同步阻塞的资源;(比如通过 http 请求查询一个数据)
- 使用
Schedulers.elastic()确保每个订阅运行在一个专门的线程上。
切换调度器
Reactor 提供了两种在响应式链中调整调度器 Scheduler 的方法:publishOn 和 subcribeOn。它们都接受一个 Scheduler 作为参数,能够改变调度器。但是 publishOn 在链中出现的位置是有讲究的,而 subscribeOn 就无所谓。
@Test
public void testScheduling() throws InterruptedException {
Flux.range(1, 10)
.map(i -> i + 1)
.log() // 1
.publishOn(Schedulers.elastic())
.filter(i -> (i % 2) == 0)
// .log() // 2
.publishOn(Schedulers.parallel())
.doOnNext(i -> System.out.println("int: " + i))
// .log() // 3
.subscribeOn(Schedulers.single())
.subscribe();
Thread.sleep(5000);
}
- 只保留这个
log()的话,源头数据流是执行在single线程池上的。

- 只保留这个
log()的话,可以看到,publishOn之后的数据流是在elastic线程池上执行的。

- 只保留这个
log()的话,可以看到,publishOn之后的数据流切换到了parallel线程池上执行。
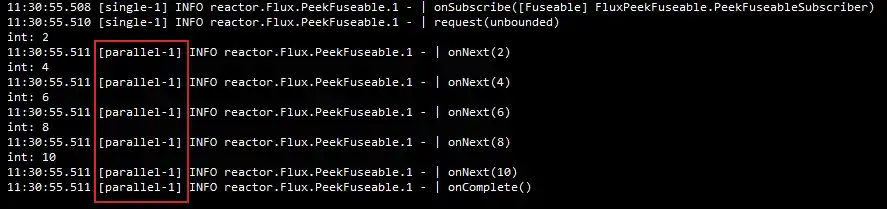
通过以上 log() 的输出,能总结出以下操作链:

publishOn会影响链中之后的操作符,比如第一个publishOn调整调度器为elastic,则filter的处理是在弹性线程池中执行的;同理,doOnNext是在 parallel 线程池中执行的;subscribeOn无论出现在什么位置,只影响源头的执行环境,也就是map方法是执行在单线程中的,直至被第一个publishOn切换调度器。
并行执行
对于一些能够在一个线程中顺序处理的任务,即使调度到 ParallelScheduler 上,通常也只由一个 Worker 来执行, 比如:
@Test
public void testParallelFlux() throws InterruptedException {
Flux.range(1, 10)
.publishOn(Schedulers.parallel())
.log()
.subscribe();
TimeUnit.SECONDS.sleep(1);
}
输出:
12:20:51.189 [main] INFO reactor.Flux.PublishOn.1 - | onSubscribe([Fuseable] FluxPublishOn.PublishOnSubscriber)
12:20:51.191 [main] INFO reactor.Flux.PublishOn.1 - | request(unbounded)
12:20:51.205 [parallel-1] INFO reactor.Flux.PublishOn.1 - | onNext(1)
12:20:51.205 [parallel-1] INFO reactor.Flux.PublishOn.1 - | onNext(2)
12:20:51.205 [parallel-1] INFO reactor.Flux.PublishOn.1 - | onNext(3)
12:20:51.205 [parallel-1] INFO reactor.Flux.PublishOn.1 - | onNext(4)
12:20:51.205 [parallel-1] INFO reactor.Flux.PublishOn.1 - | onNext(5)
12:20:51.205 [parallel-1] INFO reactor.Flux.PublishOn.1 - | onNext(6)
12:20:51.205 [parallel-1] INFO reactor.Flux.PublishOn.1 - | onNext(7)
12:20:51.205 [parallel-1] INFO reactor.Flux.PublishOn.1 - | onNext(8)
12:20:51.205 [parallel-1] INFO reactor.Flux.PublishOn.1 - | onNext(9)
12:20:51.205 [parallel-1] INFO reactor.Flux.PublishOn.1 - | onNext(10)
12:20:51.205 [parallel-1] INFO reactor.Flux.PublishOn.1 - | onComplete()
如果我们想要一些任务能够 “均匀” 分布在不同的工作线程中执行,就需要用到 ParallelFlux。
你可以对任务 Flux 使用 parallel() 操作符来得到一个 ParallelFlux。不过它本身并不会进行并行处理,而是将负载划分到多个执行 “轨道” 上(默认情况下,轨道个数与 CPU 核心数相同)。
为了配置 ParallelFlux 如何并行地执行每一个轨道,需要使用 runOn(Scheduler),Schedulers.parallel 是比较推荐的专门用于并行处理的调度器。
@Test
public void testParallelFlux() throws InterruptedException {
Flux.range(1, 10)
.parallel(3)
.runOn(Schedulers.parallel())
.log()
.subscribe();
TimeUnit.SECONDS.sleep(1);
}
输出:
12:32:57.483 [main] INFO reactor.Parallel.RunOn.1 - onSubscribe([Fuseable] FluxPublishOn.PublishOnSubscriber)
12:32:57.485 [main] INFO reactor.Parallel.RunOn.1 - request(unbounded)
12:32:57.497 [main] INFO reactor.Parallel.RunOn.1 - onSubscribe([Fuseable] FluxPublishOn.PublishOnSubscriber)
12:32:57.497 [main] INFO reactor.Parallel.RunOn.1 - request(unbounded)
12:32:57.497 [main] INFO reactor.Parallel.RunOn.1 - onSubscribe([Fuseable] FluxPublishOn.PublishOnSubscriber)
12:32:57.497 [main] INFO reactor.Parallel.RunOn.1 - request(unbounded)
12:32:57.498 [parallel-1] INFO reactor.Parallel.RunOn.1 - onNext(1)
12:32:57.498 [parallel-2] INFO reactor.Parallel.RunOn.1 - onNext(2)
12:32:57.498 [parallel-1] INFO reactor.Parallel.RunOn.1 - onNext(4)
12:32:57.498 [parallel-2] INFO reactor.Parallel.RunOn.1 - onNext(5)
12:32:57.498 [parallel-3] INFO reactor.Parallel.RunOn.1 - onNext(3)
12:32:57.498 [parallel-2] INFO reactor.Parallel.RunOn.1 - onNext(8)
12:32:57.498 [parallel-1] INFO reactor.Parallel.RunOn.1 - onNext(7)
12:32:57.498 [parallel-3] INFO reactor.Parallel.RunOn.1 - onNext(6)
12:32:57.498 [parallel-1] INFO reactor.Parallel.RunOn.1 - onNext(10)
12:32:57.498 [parallel-3] INFO reactor.Parallel.RunOn.1 - onNext(9)
12:32:57.498 [parallel-1] INFO reactor.Parallel.RunOn.1 - onComplete()
12:32:57.498 [parallel-2] INFO reactor.Parallel.RunOn.1 - onComplete()
12:32:57.498 [parallel-3] INFO reactor.Parallel.RunOn.1 - onComplete()
可以看到,各个元素的 OnNext" 均匀 “分布执行在三个线程上,最后每个线程都有独立的onComplete 事件。
Schedulers.elastic() 存在可能会创建过多线程的问题,不应该在生产环境中使用。该方法已经被标记为过时,并且会在 reactor-core3.5 版本中删除。取而代之应该使用 Schedulers.boundedElastic() 有界弹性线程池,最大线程数为 CPU 可用核心数 * 10。
Hot vs Cold
无论是 Flux 还是 Mono,都有一个特点:订阅前什么都不会发生。当我们 “创建” 了一个 Flux 的时候,我们只是 “声明”/“组装” 了它,但是如果不调用 subscribe 来订阅它,它就不会开始发出元素。
我们前面常用的 Mono.just 就属于 “冷” 的发布者。
冷序列
想象一下,你登陆 B 站打开一个喜欢的视频,你可以在任何时间开始观看,与此同时,可能有几百个人在不同的地方和你看同一个视频,它们是不同的数据流。可能我已经看到一半了,别人才刚刚开始看。B 站的视频播放就像是一个 “冷的发布者”。
冷发布者不会产生任何数据除非至少有一个人订阅它。并且它会为每个订阅者创建新的数据。
我们把这个方法当作获取视频的流数据
private Stream<String> getVideo() {
System.out.println("Got the video streaming request");
return Stream.of(
"scene 1",
"scene 2",
"scene 3",
"scene 4",
"scene 5"
);
}
videoFlux 实现如下:
// 每间隔一秒播放一个画面
Flux<String> videoFlux = Flux.fromStream(() -> getVideo())
.delayElements(Duration.ofSeconds(1));
videoFlux.subscribe(scene -> System.out.println("Tom are watching " + scene));
Thread.sleep(4000);
videoFlux.subscribe(scene -> System.out.println("Jerry are watching " + scene));
输出:
Got the video streaming request
Tom are watching scene 1
Tom are watching scene 2
Tom are watching scene 3
Got the video streaming request
Tom are watching scene 4
Jerry are watching scene 1
Tom are watching scene 5
Jerry are watching scene 2
Jerry are watching scene 3
Jerry are watching scene 4
Jerry are watching scene 5
我们发现,“Got the video streaming request” 输出了两次,说明每次新的订阅都会触发 getVideo 请求,Tom 比 Jerry 先开始看视频,当 Jerry 开始看视频时,Tom 已经看完了 3 个画面,Tom 和 Jerry 在并行地看同一个视频,但是在不同的画面。Jerry 并不会因为开始时间晚而错过任何画面。
热序列
想象有一个直播间,它不关心是否有人真的在看,一直持续地播放视频流,用户可以在它开播期间任意时间打开,并且直播间内的所有用户在同一时刻都看到同样的画面(数据),如果有人进来晚了,就只能错过之前的片段。直播间就像一个 “热的发布者”。
share
还是之前的 videoFlux,我们只需要添加一个 share,让这个 Flux” 变 “成一个直播间。share 把冷序列转换成了对多个订阅者广播数据的热序列。
// 每间隔一秒播放一个画面
Flux<String> videoFlux = Flux.fromStream(() -> getVideo())
.delayElements(Duration.ofSeconds(1))
.share();
videoFlux.subscribe(scene -> System.out.println("Tom are watching " + scene));
Thread.sleep(4000);
videoFlux.subscribe(scene -> System.out.println("Jerry are watching " + scene));
输出:
Got the video streaming request
Tom are watching scene 1
Tom are watching scene 2
Tom are watching scene 3
Tom are watching scene 4
Jerry are watching scene 4
Tom are watching scene 5
Jerry are watching scene 5
从输出来看,Jerry 因为来晚了,错过了前面 3 秒的画面,但他能和 Tom 一样观看最新的画面。
如果第二个订阅者加入时,数据已经发送完成了,那么第二个订阅会让序列重复发送流程,就像电影院中,一部影片放映完了,还会有后续的放映。
// 每间隔一秒播放一个画面
Flux<String> videoFlux = Flux.fromStream(() -> getVideo())
.delayElements(Duration.ofSeconds(1))
.share();
videoFlux.subscribe(scene -> System.out.println("Tom are watching " + scene));
// Tom 看完电影
Thread.sleep(6000);
videoFlux.subscribe(scene -> System.out.println("Jerry are watching " + scene));
输出:
Got the video streaming request
Tom are watching scene 1
Tom are watching scene 2
Tom are watching scene 3
Tom are watching scene 4
Tom are watching scene 5
Got the video streaming request
Jerry are watching scene 1
Jerry are watching scene 2
Jerry are watching scene 3
Jerry are watching scene 4
Jerry are watching scene 5
cache
如果我们不想让序列重复,可以使用 cache,它会缓存历史数据并广播给多个订阅者。
// 每间隔一秒播放一个画面
Flux<String> videoFlux = Flux.fromStream(() -> getVideo())
.delayElements(Duration.ofSeconds(1))
.cache();
videoFlux.subscribe(scene -> System.out.println("Tom are watching " + scene));
Thread.sleep(6000);
videoFlux.subscribe(scene -> System.out.println("Jerry are watching " + scene));
输出:
Got the video streaming request
Tom are watching scene 1
Tom are watching scene 2
Tom are watching scene 3
Tom are watching scene 4
Tom are watching scene 5
Jerry are watching scene 1
Jerry are watching scene 2
Jerry are watching scene 3
Jerry are watching scene 4
Jerry are watching scene 5
可以看到,getVideo() 只调用了一次,但是 Jerry 仍然可以观看的所有的画面,cache 为以后的订阅者缓存了所有的数据。
如果不想缓存,可以使用 cache(0)。
输出:
Got the video streaming request
Tom are watching scene 1
Tom are watching scene 2
Tom are watching scene 3
Tom are watching scene 4
Tom are watching scene 5
此时的 Jerry

总结
- 冷序列:不管订阅者在何时订阅,都能收到数据流中的全部数据。
- 热序列:热序列持续产生数据,订阅者只能获取到其订阅之后的数据。