
简介
Spring WebFlux 是 Spring 在 5.0 版本后提供的一套 非阻塞异步 开发框架,它的核心是基于 Reactor 相关 API 实现的,能够运行在 Netty、Undertow 以及 3.1 + 版本的的 Servlet 容器上。
Spring WebFlux 与 Spring MVC

WebFlux 是异步非阻塞 IO 模型,只需少量的工作线程就能够处理并响应请求,无需阻塞等待方法返回,提高了并发处理请求的能力,即系统吞吐量。
WebMVC 的实现是阻塞 IO,其容器维护一个线程池来处理每一个用户请求,线程池有限的连接数和请求阻塞的处理过程,形成了系统吞吐量的瓶颈。
Tips: 并不是说项目使用了 WebFlux 进行开发,就能发挥出非阻塞的优势,还需要第三方库的支持,比如上面的 MongoDB,Redis,需要使用他们提供的 ReactiveAPI 进行开发。
五种 IO 模型
为了便于理解 IO 模型的基本概念,我们以应用之间的消息通信举例。

- 应用 A 把消息发送到 TCP 发送缓冲区。
- TCP 发送缓冲区再把消息发送出去,经过网络传递后,消息会发送到 B 服务器的 TCP 接收缓冲区。
- 应用 B 从 TCP 接收缓冲区中读取属于自己的数据。
阻塞 IO 模型
阻塞 IO 是当应用 B 发起读取数据申请时,在内核数据没有准备好之前,应用 B 会一直处于等待数据状态,直到内核把数据准备好了交给应用 B 才结束。
非阻塞 IO 模型
非阻塞 IO 是当应用 B 发起读取数据申请时,如果内核数据没有准备好会立即告诉应用 B,不会让 B 在这里等待。 但是需要应用 B 不断发起读取数据申请,直到读取到需要的数据为止。这样会造成一定的资源浪费。
复用 IO 模型
思考一个问题:
如果在并发环境下,有 N 个人向应用 B 发送消息,应用 B 就需要创建多个线程去读取数据,情况如下图:
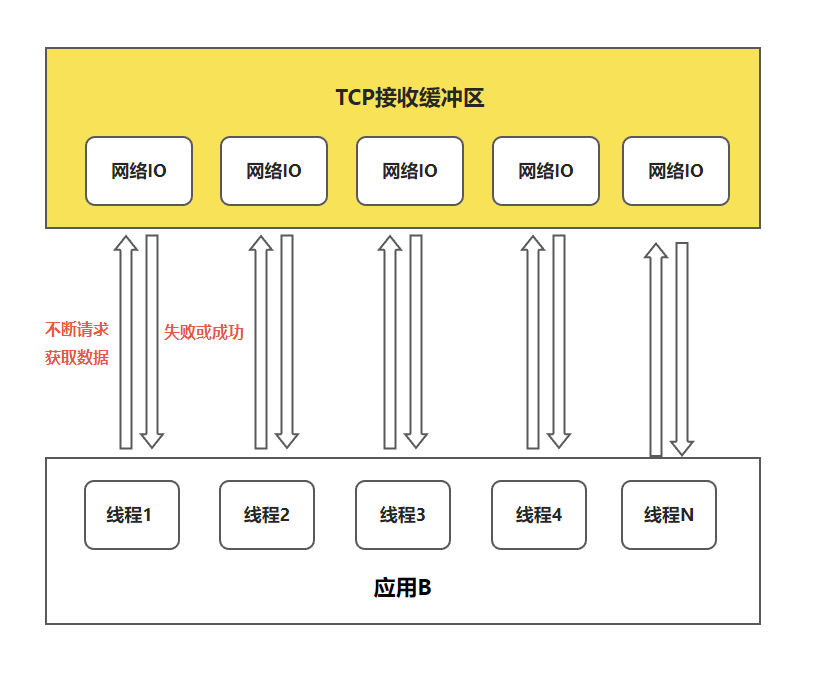
并发情况下服务器很可能一瞬间收到几十万的请求,应用 B 就需要创建几十万个线程去读取数据,同时因为线程不知道数据什么时候准备好,为了确保消息能即使读取到,那么这些线程自己会不断请求获取数据。
先不说服务器能不能扛得住这么多线程,就算扛得住,这种方式也非常浪费资源,大量的线程用于读取数据,意味着能做其它事情的线程就会变少。
那能不能提供一种方式,可以由一个线程监控多个网络请求,当有数据准备就绪之后再分配对应的线程去读取数据,这样就能节省出大量的线程资源,这个就是 IO 复用模型的思路。

正如上图,IO 复用模型的思路就是提供了一种函数可以同时监控多个 fd 的操作,这个函数正是我们常说到的 select、poll、epoll 函数,select 函数监控的 fd 中只要有任何一个数据状态准备就绪,select 就会返回可读状态,这时询问线程再去通知处理数据的线程,对应线程再去发起请求读取数据。
总结: 复用 IO 的基本思路就是通过 slect 或 poll、epoll 来监控多 fd ,来达到不必为每个 fd 创建一个对应的监控线程,从而减少线程资源创建的目的。
信号驱动 IO 模型
复用 IO 模型可以通过一个线程监控多个 fd,但由于是采用轮询的方式,大部分情况下的轮询都是无效的,而且随着监控的 fd 越来越多,效率也直线下降。那么能不能不要我总是去询问你数据有没有准备好,而是你数据就绪之后就通知后,由此衍生了信号驱动 IO 模型。
信号驱动 IO 是在调用 sigaction 的时候建立一个 SIGIO 信号联系,当数据准备好之后通过 SIGIO 信号通知线程,线程收到数据就绪的状态后,再发起读取数据的请求,因为信号驱动 IO 模型下的应用线程在发出信号监控后可立即返回,不会阻塞,所以这样的方式下,一个应用线程也可以监控多个 fd。
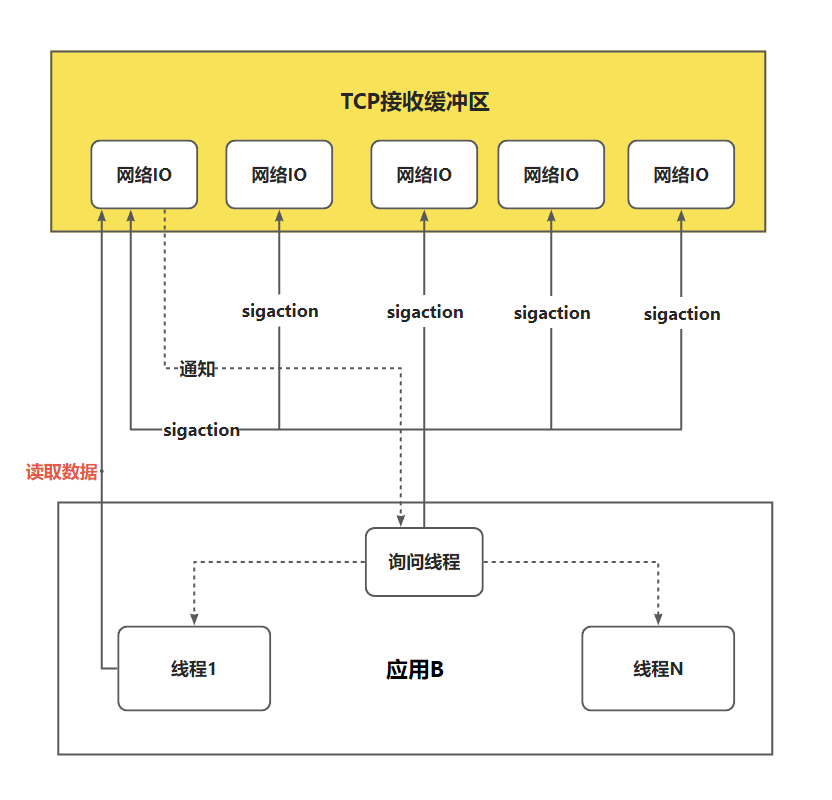
总结: 信号驱动 IO 模型通过这种建立信号关联的方式,实现了发出请求后只需要等待数据就绪的通知,这样就可以避免大量无效的数据状态轮询操作。
异步 IO 模型
通过观察发现,不管是 IO 复用还是信号驱动,我们要获取数据总是要发起两个阶段的请求,第一次发送请求询问数据状态是否准备好,第二次发送请求读取数据。

于是有人设计了一种方案,应用只需要发送一个获取数据请求,告诉内核它要读取数据后立刻返回,内核收到请求后建立一个信号联系,当数据准备就绪后,内核会主动把数据复制到用户空间,等所有操作完成之后,内核会发起一个通知告诉应用,这种一劳永逸的模式就是异步 IO 模型。
总结: 在异步 IO 的模型下,只需要发送一次读取请求就可以完成状态询问和数据拷贝的所有操作。