
自定义数据流
我们可以通过定义相应的事件(onNext、onError 和 onComplete)创建一个 Flux 或 Mono。Reactort 提供了 generate、create、push 和 handle 等方法,所有这些方法都使用 sink(池)来生成数据流。
sink,顾名思义,就是池子,可以想象一下厨房水池的样子。如图所示:

sink 通常至少会暴露三个方法给我们,next、error 和 complete。next 和 error 相当于两个下水口,我们不断将自定义的数据放到 next 口,Reactor 就会帮我们串成一个 publisher 数据流,直到有一个错误数据放到 error 口,或者按了一下 compelete 按钮,数据流就会终止了。
Flux Create
create 方法接受一个 FluxSink<T> 消费者,也就是说,你需要提供一个 FluxSink 的实例用来给下游的订阅者们发送 0 到 N 个元素。每个订阅者都会获得一个 FluxSink 的实例发送元素。
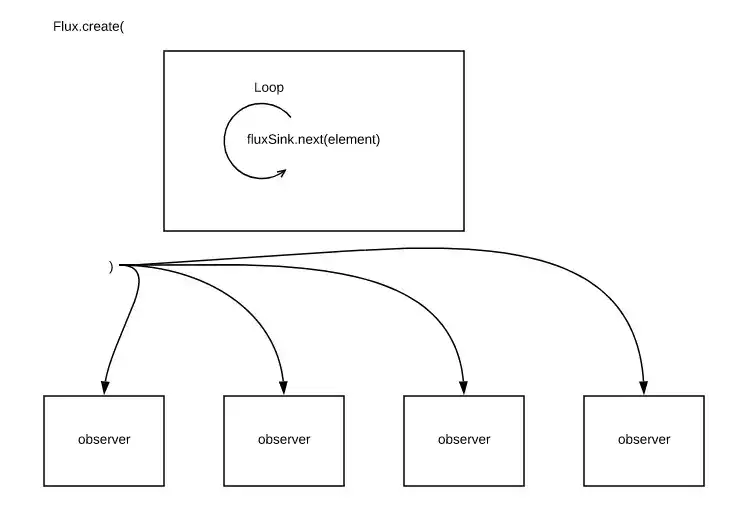
这个例子用 Flux.create 创建了一个序列。
Flux<Integer> integerFlux = Flux.create((FluxSink<Integer> fluxSink) -> {
IntStream.range(0, 5)
.peek(i -> System.out.println("going to emit - " + i))
.forEach(fluxSink::next);
});
我们有两个下游的订阅者
//First observer. takes 1 ms to process each element
integerFlux.delayElements(Duration.ofMillis(1)).subscribe(i -> System.out.println("First: " + i));
//Second observer. takes 2 ms to process each element
integerFlux.delayElements(Duration.ofMillis(2)).subscribe(i -> System.out.println("Second: " + i));
输出:
going to emit - 0
going to emit - 1
going to emit - 2
going to emit - 3
going to emit - 4
going to emit - 0
going to emit - 1
going to emit - 2
going to emit - 3
going to emit - 4
First: 0
Second: 0
First: 1
Second: 1
First: 2
Second: 2
First: 3
Second: 3
Second: 4
First: 4
通过输出我们可以发现
- 每个订阅者都有自己的
FluxSink实例,正如我们期望的创建了一个冷的发布者。 create不会等待订阅者处理元素,它甚至可能在订阅者开始处理前就发送元素。
如果订阅者的处理速度跟不上怎么办?create 能够额外接受一个定义数据溢出时处理策略的参数,默认的策略是 buffer。
具体能选择的策略有:
- BUFFER:缓存下游没来得及处理的元素(如果缓存不限大小可能导致 OOM)。
- DROP:当下游没有准备好接收新的元素时丢弃这个元素。
- ERROR:当下游来不及处理时抛出
IllegalStateException。 - IGNORE:完全忽略下游的背压请求。
- LATEST:下游只会获得上游最新的元素。
如果需要的话,我们也可以在 create 方法之外获取 FluxSink 实例的引用并且发送元素,它不是必须要发生在 create 方法内。
一个简易的 FluxSink 消费者实现:
public class FluxSinkImpl implements Consumer<FluxSink<Integer>> {
private FluxSink<Integer> fluxSink;
@Override
public void accept(FluxSink<Integer> integerFluxSink) {
this.fluxSink = integerFluxSink;
}
public void publishEvent(int event) {
this.fluxSink.next(event);
}
}
发送元素:
// 创建一个 FluxSink 实例
FluxSinkImpl fluxSinkConsumer = new FluxSinkImpl();
//create 方法能够传入这个实例
Flux<Integer> integerFlux = Flux.create(fluxSinkConsumer)
.delayElements(Duration.ofMillis(1)).share();
integerFlux.delayElements(Duration.ofMillis(1)).subscribe(i -> System.out.println("First: " + i));
integerFlux.delayElements(Duration.ofMillis(2)).subscribe(i -> System.out.println("Second: " + i));
// 在这里发送元素
IntStream.range(0, 5)
.forEach(fluxSinkConsumer::publishEvent);
输出:
Second: 0
First: 0
Second: 1
First: 1
First: 2
Second: 2
First: 3
Second: 3
First: 4
Second: 4
Flux Generate
generate 与 create 稍微有些不同,它接收一个 SynchronousSink<T> 的消费者,在上面的 create 方法,我们可以通过消费者发送 0 到 N 个元素,但是在 generate 方法,我们只能发送一个元素。
是否意味着这个 flux 最多只能发送一个元素?
并不是,generate 方法也能发送 无限数量的元素。generate 方法能够基于下游的请求一个接一个地发送元素。消费者自己不能循环地发送元素,如果订阅者对后续的元素不敢兴趣,那么 generate 也不会发送元素。
为了更好地便于理解它们的行为,试着运行以下代码。
Create
Flux<Integer> integerFlux = Flux.create((FluxSink<Integer> fluxSink) -> {
System.out.println("Flux create");
IntStream.range(0, 100)
.peek(i -> System.out.println("going to emit - " + i))
.forEach(fluxSink::next);
});
integerFlux.delayElements(Duration.ofMillis(50))
.subscribe(i -> System.out.println("First consumed: " + i));
输出:
Flux create
going to emit - 0
going to emit - 1
going to emit - 2
going to emit - 3
going to emit - 4
going to emit - 5
going to emit - 6
going to emit - 7
going to emit - 8
going to emit - 9
going to emit - 10
going to emit - 11
going to emit - 12
........
going to emit - 91
going to emit - 92
going to emit - 93
going to emit - 94
going to emit - 95
going to emit - 96
going to emit - 97
going to emit - 98
going to emit - 99
First consumed: 0
First consumed: 1
First consumed: 2
First consumed: 3
First consumed: 4
First consumed: 5
First consumed: 6
First consumed: 7
First consumed: 8
First consumed: 9
First consumed: 10
........
First consumed: 94
First consumed: 95
First consumed: 96
First consumed: 97
First consumed: 98
First consumed: 99
- 在上面的消费者
FluxSink<Integer>,它有一个循环持续地发送元素。 - “Flux create” 只执行了一次。
- “going to emit” 语句执行了 100 次。
- 然后所有的 “First consumed” 一个接一个地执行。
Generate
AtomicInteger atomicInteger = new AtomicInteger();
// Flux generate sequence
Flux<Integer> integerFlux = Flux.generate((SynchronousSink<Integer> synchronousSink) -> {
System.out.println("Flux generate");
synchronousSink.next(atomicInteger.getAndIncrement());
});
integerFlux.delayElements(Duration.ofMillis(100))
.subscribe(i -> System.out.println("First consumed: " + i));
输出
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
First consumed: 0
First consumed: 1
First consumed: 2
First consumed: 3
First consumed: 4
First consumed: 5
First consumed: 6
First consumed: 7
First consumed: 8
First consumed: 9
First consumed: 10
First consumed: 11
First consumed: 12
First consumed: 13
First consumed: 14
First consumed: 15
First consumed: 16
First consumed: 17
First consumed: 18
First consumed: 19
First consumed: 20
First consumed: 21
First consumed: 22
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
First consumed: 23
First consumed: 24
First consumed: 25
First consumed: 26
First consumed: 27
First consumed: 28
First consumed: 29
First consumed: 30
First consumed: 31
First consumed: 32
First consumed: 33
First consumed: 34
First consumed: 35
First consumed: 36
First consumed: 37
First consumed: 38
First consumed: 39
First consumed: 40
First consumed: 41
First consumed: 42
First consumed: 43
First consumed: 44
First consumed: 45
First consumed: 46
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
Flux generate
.........
- “Flux generate” 执行了 32 次。
- “First consumed” 执行了 23 次。
- 又是一堆 “Flux generate”。
- 然后又是一堆 “First consumed”。
generate 方法是基于下游的请求发送元素,它首先生成了 32 个元素并且缓存,当下游开始处理元素并且缓冲区的容量小于阈值时,它会再发一些元素。这个过程会一直重复,但有一点要注意,如果订阅者停止处理元素,Flux.generate 也会停止发送元素。所以 generate 方法能知道下游订阅者的处理速度。
我们试一下同时发送两个元素
AtomicInteger atomicInteger = new AtomicInteger();
Flux<Integer> integerFlux = Flux.generate((SynchronousSink<Integer> synchronousSink) -> {
System.out.println("Flux generate");
synchronousSink.next(atomicInteger.getAndIncrement());
synchronousSink.next(atomicInteger.getAndIncrement());
});
输出:
Flux generate
00:13:56.698 [main] ERROR reactor.core.publisher.Operators - Operator called default onErrorDropped
reactor.core.Exceptions$ErrorCallbackNotImplemented: java.lang.IllegalStateException: More than one call to onNext
Caused by: java.lang.IllegalStateException: More than one call to onNext
使用 SynchronousSink 发送超过一个元素是非法的。
因为我们不能发送多个元素,所以就算我们获取到 SynchronousSink 的引用也是没有意义的。
如果需要的话,generate 方法可以维护一个状态。
// initial state
Callable<Integer> initialState = () -> 65;
BiFunction<Integer, SynchronousSink<Character>, Integer> generator = (state, sink) -> {
char value = (char) state.intValue();
sink.next(value);
if (value == 'Z') {
sink.complete();
}
return state + 1;
};
// Flux which accepts initialState and bifunction as arg
Flux<Character> charFlux = Flux.generate(initialState, generator);
charFlux.delayElements(Duration.ofMillis(50))
.subscribe(i -> System.out.println("Consumed: " + i));
输出:
Consumed: A
Consumed: B
Consumed: C
Consumed: D
Consumed: E
Consumed: F
Consumed: G
Consumed: H
Consumed: I
Consumed: J
Consumed: K
Consumed: L
Consumed: M
Consumed: N
Consumed: O
Consumed: P
Consumed: Q
Consumed: R
Consumed: S
Consumed: T
Consumed: U
Consumed: V
Consumed: W
Consumed: X
Consumed: Y
Consumed: Z
Flux Create
- 入参为
Consumer<FluxSink<T>> Consumer只能被调用一次Consumer马上发送 0 到 N 个元素- 发布者不清楚下游的状态,所以我们需要提供一个
OverflowStrategy作为额外的参数 - 我们可以拿到
FluxSink的引用持续地发送元素,必要的话多线程也可以
Flux Generate
- 入参为
Consumer<SynchronousSink<T>> Consumer可以基于下游的请求一遍一遍被调用Consumer只能发送一个元素- 发布者基于下游的请求生成元素
- 我们能拿到
SynchronousSink的引用,但没啥用,因为我们只能发送一个元素
背压机制
什么是背压
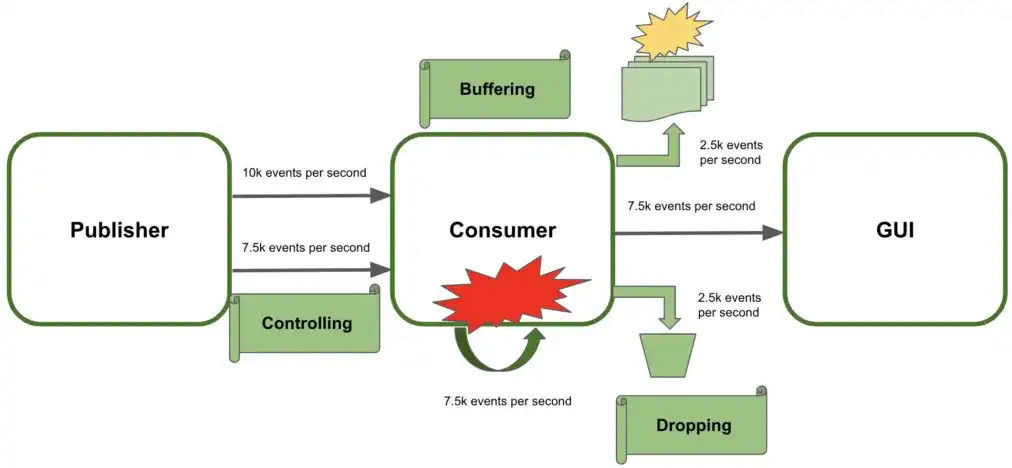
在响应式数据流中,背压定义了如何调节数据流元素的传输。换句话说,控制消费者能接收到的数据量。 我们用一个例子来说明:

- 这个系统包含发布者,消费者,GUI
- 发布者每秒发送 10000 个数据给消费者
- 消费者处理数据并把结果发送给 GUI
- GUI 对用户展示结果
- 消费者每秒只能处理 7500 个数据
在这个速率下,消费者没有控制数据发送(背压),因此,这个系统会崩溃,用户也不会看到结果。
背压预防系统故障
这里我们可以用一些背压策略来预防系统故障,来管理额外接收到的数据:
- 首先我们会想到 控制数据流的发送 ,发布者需要减缓发布数据的速度。这样,消费者就不会过载,不过,这并不总是可行的,我们得找到其他的选项。
- 缓存额外的数据元素 。用这种方式,消费者缓存剩下的数据元素直到它能够处理为止。主要的缺点是可能会导致内存崩溃。
- 丢弃额外的元素 。虽然这个解决办法也不是很理想,不过这样至少系统不会崩溃。
背压控制
我们应该专注于让发布者控制数据的发送。有以下策略:
- 当订阅者请求时才发送新的数据 。这是一个拉取的策略。
- 限制客户端能够接收到元素的数量 。作为限制的推送策略,发布者每次只能向客户端发送不超过指定数量的元素。
- 当消费者不能处理更多的数据时取消数据流 。这种情况下,接收者能在任何给定的时间终止数据传输并在稍后重新订阅流。
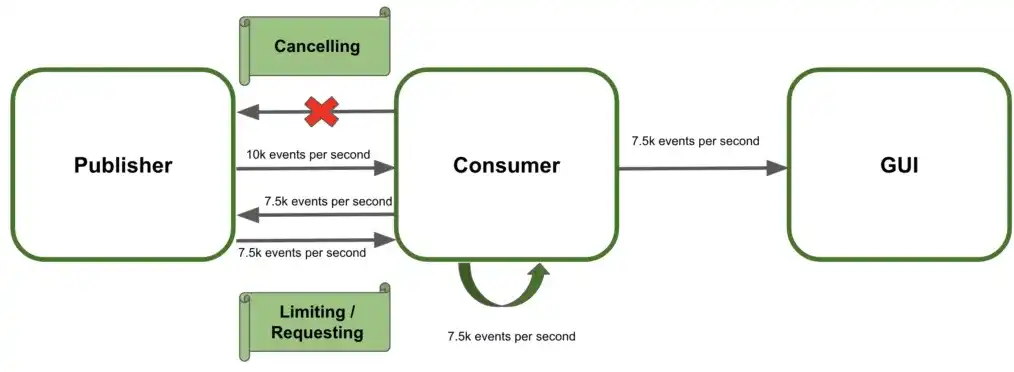
背压机制的实现
Request
@Test
public void testRequest() {
Flux<Integer> intRange = Flux.range(1, 100);
//gets only 10 elements
intRange.subscribe(
System.out::println,
Throwable::printStackTrace,
() -> System.out.println("==== Completed ===="),
subscription -> subscription.request(10)
);
}
输出:
1
2
3
4
5
6
7
8
9
10
用这种方式,消费者永远不会被发布者的数据压垮。换句话说,消费者在控制它能处理的数据元素。
Limit
先看下不做限制默认的情况
Flux.range(1, 100)
.log()
.delayElements(Duration.ofMillis(100))
.subscribe(System.out::println);
输出:
00:05:21.718 [main] INFO reactor.Flux.Range.1 - | onSubscribe([Synchronous Fuseable] FluxRange.RangeSubscription)
00:05:21.720 [main] INFO reactor.Flux.Range.1 - | request(32)
00:05:21.720 [main] INFO reactor.Flux.Range.1 - | onNext(1)
00:05:21.755 [main] INFO reactor.Flux.Range.1 - | onNext(2)
00:05:21.756 [main] INFO reactor.Flux.Range.1 - | onNext(3)
......
00:05:21.756 [main] INFO reactor.Flux.Range.1 - | onNext(32)
1
2
3
......
23
00:05:23.198 [parallel-3] INFO reactor.Flux.Range.1 - | request(24)
00:05:23.199 [parallel-3] INFO reactor.Flux.Range.1 - | onNext(33)
......
00:05:23.204 [parallel-3] INFO reactor.Flux.Range.1 - | onNext(56)
24
25
26
......
47
00:05:24.715 [parallel-7] INFO reactor.Flux.Range.1 - | request(24)
00:05:24.715 [parallel-7] INFO reactor.Flux.Range.1 - | onNext(57)
......
00:05:24.721 [parallel-7] INFO reactor.Flux.Range.1 - | onNext(79)
00:05:24.721 [parallel-7] INFO reactor.Flux.Range.1 - | onNext(80)
48
......
71
00:05:26.232 [parallel-11] INFO reactor.Flux.Range.1 - | request(24)
00:05:26.232 [parallel-11] INFO reactor.Flux.Range.1 - | onNext(81)
......
00:05:26.233 [parallel-11] INFO reactor.Flux.Range.1 - | onNext(98)
00:05:26.233 [parallel-11] INFO reactor.Flux.Range.1 - | onNext(99)
00:05:26.233 [parallel-11] INFO reactor.Flux.Range.1 - | onNext(100)
00:05:26.235 [parallel-11] INFO reactor.Flux.Range.1 - | onComplete()
72
......
95
00:05:27.751 [parallel-15] INFO reactor.Flux.Range.1 - | request(24)
96
97
98
99
100
- 默认情况下,上游会收到一个获取 32 个元素的请求,32 个元素生产并发布给下游
- 一旦下游的 24 个元素被耗尽(日志可能显示 23,但它应该是 24。因为第 24 个元素被
delayElement操作符延迟),上游收到另一个获取 24 个元素的请求 - 它会一直重复直到上游发送完成或者错误信号
限制每次只能请求 10 个元素
Flux.range(1, 100)
.log()
.limitRate(10)
.delayElements(Duration.ofMillis(100))
.subscribe(System.out::println);

输出:
00:17:08.045 [main] INFO reactor.Flux.Range.1 - | onSubscribe([Synchronous Fuseable] FluxRange.RangeSubscription)
00:17:08.048 [main] INFO reactor.Flux.Range.1 - | request(10)
00:17:08.048 [main] INFO reactor.Flux.Range.1 - | onNext(1)
......
00:17:08.085 [main] INFO reactor.Flux.Range.1 - | onNext(10)
1
2
3
4
5
6
7
00:17:08.514 [parallel-7] INFO reactor.Flux.Range.1 - | request(8)
00:17:08.514 [parallel-7] INFO reactor.Flux.Range.1 - | onNext(11)
......
......
......
......
00:17:13.623 [parallel-7] INFO reactor.Flux.Range.1 - | onNext(98)
88
89
90
91
92
93
94
95
00:17:14.126 [parallel-15] INFO reactor.Flux.Range.1 - | request(8)
00:17:14.127 [parallel-15] INFO reactor.Flux.Range.1 - | onNext(99)
00:17:14.127 [parallel-15] INFO reactor.Flux.Range.1 - | onNext(100)
00:17:14.130 [parallel-15] INFO reactor.Flux.Range.1 - | onComplete()
96
97
98
99
100
一旦有 75% 的数据被发出,它就会自动请求并重新装满该数额。这就是为什么我们首先看到请求 10 个元素,之后每次都会看到请求 8 个元素。
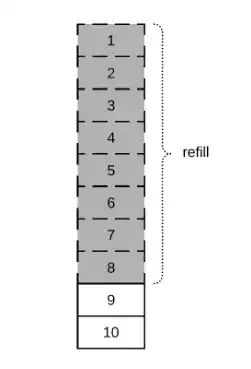
Cancel
更好地控制数据流的方式是在需要的时候取消订阅。你可以用 BaseSubscriber::hookOnNext 订阅生产者。
参考下面的例子,生产者只有在订阅者发送 request(1) 时才会发送下一个元素。实际上,这个生产者可以是一个数据库,而订阅者可以是一个 I/O 设备。为了配置运算的速度,I/O 设备可以请求一批数据并处理,然后再请求下一批数据,以此类推。
@Test
public void cancelCallback() {
Flux<Integer> intRange = Flux.range(1, 100).log();
intRange.doOnCancel(() -> System.out.println("===== Cancel method invoked ======="))
.doOnComplete(() -> System.out.println("==== Completed ===="))
.subscribe(new BaseSubscriber<Integer>() {
@Override
protected void hookOnNext(Integer value) {
try {
Thread.sleep(500);
//request next element
request(1);
System.out.println(value);
if (value == 5) {
cancel();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
输出:
00:11:07.921 [main] INFO reactor.Flux.Range.1 - | onSubscribe([Synchronous Fuseable] FluxRange.RangeSubscription)
00:11:07.922 [main] INFO reactor.Flux.Range.1 - | request(unbounded)
00:11:07.923 [main] INFO reactor.Flux.Range.1 - | onNext(1)
00:11:08.431 [main] INFO reactor.Flux.Range.1 - | request(1)
1
00:11:08.431 [main] INFO reactor.Flux.Range.1 - | onNext(2)
00:11:08.935 [main] INFO reactor.Flux.Range.1 - | request(1)
2
00:11:08.936 [main] INFO reactor.Flux.Range.1 - | onNext(3)
00:11:09.450 [main] INFO reactor.Flux.Range.1 - | request(1)
3
00:11:09.450 [main] INFO reactor.Flux.Range.1 - | onNext(4)
00:11:09.954 [main] INFO reactor.Flux.Range.1 - | request(1)
4
00:11:09.954 [main] INFO reactor.Flux.Range.1 - | onNext(5)
00:11:10.460 [main] INFO reactor.Flux.Range.1 - | request(1)
5
===== Cancel method invoked =======
00:11:10.463 [main] INFO reactor.Flux.Range.1 - | cancel()
00:11:10.484 [main] INFO reactor.Flux.Range.1 - | onSubscribe([Synchronous Fuseable] FluxRange.RangeSubscription)
00:11:10.486 [main] INFO reactor.Flux.Range.1 - | request(unbounded)
00:11:10.486 [main] INFO reactor.Flux.Range.1 - | onNext(1)
00:11:10.486 [main] INFO reactor.Flux.Range.1 - | onNext(2)
00:11:10.486 [main] INFO reactor.Flux.Range.1 - | onNext(3)
00:11:10.486 [main] INFO reactor.Flux.Range.1 - | onNext(4)
00:11:10.486 [main] INFO reactor.Flux.Range.1 - | onNext(5)
00:11:10.486 [main] INFO reactor.Flux.Range.1 - | cancel()
深入理解响应式流
响应式流规范
2013 年末的时候,Netflix、Pivotal、Typesafe 等公司的工程师们共同发起了关于制定 响应流规范(Reactive Stream Specification) 的倡议和讨论,并在 Github 上创建了 reactive-streams-jvm 项目。项目 README 就是规范正文。
了解这一规范对我们理解和使用开发库也是很有帮助的,因为规范的内容都是对响应式编程思想精髓的呈现。其中包括定义的响应式流的特点:
- 具有处理无限数量元素的能力
- 按序处理
- 异步地传递元素
- 必须实现非阻塞的背压
响应式流接口
响应式流规范定义了四个接口:
Publisher是能够发出元素的发布者。
public interface Publisher<T> {
public void subscribe(Subscriber<? super T> s);
}
Subscriber是接收元素并响应的订阅者
public interface Subscriber<T> {
public void onSubscribe(Subscription s);
public void onNext(T t);
public void onError(Throwable t);
public void onComplete();
}
当执行 subscribe 方法时,发布者会回调订阅者的 onSubscribe 方法,这个方法中,通常订阅者会借助传入的 Subscription 向发布者请求 n 个数据。然后发布者通过不断调用订阅者的 onNext 方法向订阅者发出最多 n 个数据。如果数据全部发送完,则会调用 onComplete 信号告知订阅者流已经发完;如果有错误发生,则通过 onError 发出错误信号并终止数据流。

Subscription是Publisher和Subscriber的 “中间人”。
public interface Subscription {
public void request(long n);
public void cancel();
}
当发布者调用 subscribe 方法注册订阅者时,会通过订阅者的 onSubscribe 传入 Subscription 对象,之后订阅者就可以使用这个 Subscription 对象的 request 方法向发布者请求元素。背压机制也正是基于此来实现的,因此第 4 个特点也实现了。
订阅之后发生了什么
在 Reactor 中,我们最先接触的生成 Publisher 的方法就是 Flux.just(),下面我们来手写代码模拟一下 Reactor 的实现方式,帮助理解。
首先,确保项目引入了响应流规范的四个接口定义。
<dependency>
<groupId>org.reactivestreams</groupId>
<artifactId>reactive-streams</artifactId>
<version>1.0.4</version>
</dependency>
先创建一个最最基础的类 Flux,它是一个 Publisher。
package com.opoa.reactive.core;
import org.reactivestreams.Publisher;
import org.reactivestreams.Subscriber;
public abstract class Flux<T> implements Publisher<T> {
@Override
public abstract void subscribe(Subscriber<? super T> s);
}
在 Reactor 中,Flux 既是一个发布者,又充当工具类的角色,当我们使用 Flux.just()、 Flux.range() 等工厂方法生成 Flux 时,会 new 一个新的 Flux,比如 Flux.just() 会返回一个 FluxArray 对象。
public static <T> Flux<T> just(T... data) {
return new FluxArray<>(data);
}
返回的 FluxArray 对象是 Flux.just 生成的 Publisher,它继承自 Flux,并实现了 subscribe 方法。
public class FluxArray<T> extends Flux<T> {
private T[] array; // 1
public FluxArray(T[] data) {
this.array = data;
}
@Override
public void subscribe(Subscriber<? super T> actual) {
actual.onSubscribe(new ArraySubscription<>(actual, array)); // 2
}
}
FluxArray内部使用一个数组来保存数据subscribe方法通常会回调Subscriber的onSubscribe方法,该方法需要传入一个Subscription对象,从而订阅者之后可以通过回调传回的Subscription的request方法跟FluxArray请求数据。
继续编写 ArraySubscription:
public class FluxArray<T> extends Flux<T> {
......
static class ArraySubscription<T> implements Subscription { // 1
final Subscriber<? super T> actual;
final T[] array; // 2
int index;
boolean canceled;
public ArraySubscription(Subscriber<? super T> actual, T[] array) {
this.actual = actual;
this.array = array;
}
@Override
public void request(long n) {
if (canceled) {
return;
}
int length = array.length;
for (int i = 0; i < n && index < length; i++) {
actual.onNext(array[index++]); // 3
}
if (index == length) {
actual.onComplete(); // 4
}
}
@Override
public void cancel() { // 5
this.canceled = true;
}
}
}
ArraySubscription是一个静态内部类。我们可以把它当成普通的类,只不过恰好定义在其他类的内部- Subscription 中也保存有一份数据
- 当有可以发出的元素时,回调订阅者的
onNext方法传递元素 - 当所有的元素都发送完后,回调订阅者的
onComplete方法 - 订阅者可以使用
Subscription取消订阅
至此,发布者就开发完了。我们来测试一下:
@Test
public void fluxArrayTest() {
Flux.just(1, 2, 3, 4).subscribe(new Subscriber<Integer>() { // 1
@Override
public void onSubscribe(Subscription s) {
System.out.println("onSubscribe");
s.request(5); // 2
}
@Override
public void onNext(Integer integer) {
System.out.println("onNext: " + integer);
}
@Override
public void onError(Throwable t) {
}
@Override
public void onComplete() {
System.out.println("onComplete");
}
});
}
Subscriber通过匿名内部类定义,需要实现接口的四个方法- 订阅时请求 5 个元素
输出:
onSubscribe
onNext: 1
onNext: 2
onNext: 3
onNext: 4
onComplete
请求 3 个元素的时候,输出如下:
onSubscribe
onNext: 1
onNext: 2
onNext: 3
没有完成事件,至此,一个简单的 Flux.just 就完成了,通过这个例子我们能初步总结一下:
- 工厂方法返回的是
Flux子类的实例,如FluxArray FluxArray的subscribe方法会返回给订阅者一个Subscription实现类的对象,这个ArraySubscription是FluxArray的静态内部类,它定义了 “如何发布元素” 的逻辑- 订阅者可以通过这个
ArraySubscription对象向发布者请求 n 个数据,发布者也可以借助这个ArraySubscription对象向订阅者传递数据元素(onNext/onError/onComplete)。

上图的这个过程基本适用于大多数的用于生成 Flux/Mono 的静态工厂方法,如 Flux.just、Flux.range 等等。
首先,使用类似 Flux.just 的方法创建发布者后,会创建一个具体的发布者(Publisher),如 FluxArray。
- 当使用
.subscribe订阅这个发布者时,首先会 new 一个具有相应逻辑的Subscription(如ArraySubscription,这个Subscription定义了如何处理下游的request,以及如何发出元素) - 然后发布者将这个
Subscription通过订阅者的onSubscribe方法传给订阅者 - 在订阅者的.
onSubscribe方法中,需要通过Subscription发起第一次请求request Subscription收到请求,就通过回调订阅者的onNext方法发出元素,有多少发多少,但不能超过请求的个数- 订阅者在
onNext中定义对元素的处理逻辑,处理完成之后,可以继续发起请求 - 发布者根据需求继续满足订阅者的请求
- 直至发布者的序列全部结束,通过订阅者的
onComplete予以告知,当然如果序列在发送过程中有错误产生,则通过订阅者的onError告知错误信号,这两种情况都将终止序列。
操作符 “流水线”
响应式开发库的一个很赞的特性就是可以像组装流水线一样将操作符串起来,用来声明复杂的处理逻辑。比如:
Flux.just(1, 2, 3, 4, 5)
.map(i -> i * i)
.filter(i -> (i % 2) == 0)
.subscribe(System.out::println);
通过源码,我们可以了解这种 “流水线” 的实现机制。下面我们来模拟一下 Reactor 中 Flux.map 的实现方式。
Flux.map 用于实现转换,转换后的元素类型可能会发生变化,转换的逻辑由 Function 决定。方法本身返回的是一个转换后的 Flux,基于此,实现如下:
public abstract class Flux<T> implements Publisher<T> {
......
public <V> Flux<V> map(Function<? super T, ? extends V> mapper) { // 1
return new FluxMap<>(this, mapper); // 2
}
}
- 泛型方法,通过泛型表示可能出现的类型变换(T —> V)
FluxMap就是新的Flux
既然 FluxMap 是一个新的 Flux,那么与 FluxArray 类似,其内部定义有 MapSubscription,这是一个 Subscription,能够根据其订阅者的请求发出数据。
public class FluxMap<T, R> extends Flux<R> {
private final Flux<? extends T> source;
private final Function<? super T, ? extends R> mapper;
public FluxMap(Flux<? extends T> source, Function<? super T, ? extends R> mapper) {
this.source = source;
this.mapper = mapper;
}
@Override
public void subscribe(Subscriber<? super R> actual) {
}
static final class MapSubscriber<T, R> implements Subscription {
private final Subscriber<? super R> actual;
private final Function<? super T, ? extends R> mapper;
MapSubscriber(Subscriber<? super R> actual, Function<? super T, ? extends R> mapper) {
this.actual = actual;
this.mapper = mapper;
}
@Override
public void request(long n) { // 1
//todo 收到请求 发出元素
}
@Override
public void cancel() {
//todo 取消订阅
}
}
}
map操作符并不产生数据,只是数据的搬运工。收到request后要发出的数据来自上游。
所以 MapSubscriber 同时也应该是一个订阅者,它订阅上游的发布者,并将数据传递给下游的订阅者。

对下游作为发布者,传递上游的数据到下游,对上游是订阅者,传递下游的请求到上游。
static final class MapSubscriber<T, R> implements Subscriber<T>, Subscription { // 1
...
}
- 所以我们既需要实现
Subscription,也需要实现Subscriber。
这样,总共有 6 个方法要实现:来自 Subscriber 接口的 onSubscribe、onNext、onError、onComplete,来自 Subscription 接口的 request 和 cancel。下面我们将实现这几个方法。
@Override
public void subscribe(Subscriber<? super R> actual) {
source.subscribe(new MapSubscriber<>(actual, mapper));
}
static final class MapSubscriber<T, R> implements Subscriber<T>, Subscription {
private final Subscriber<? super R> actual;
private final Function<? super T, ? extends R> mapper;
boolean done;
Subscription subscriptionOfUpstream;
MapSubscriber(Subscriber<? super R> actual, Function<? super T, ? extends R> mapper) {
this.actual = actual;
this.mapper = mapper;
}
@Override
public void onSubscribe(Subscription s) {
this.subscriptionOfUpstream = s; // 1
actual.onSubscribe(this); // 2
}
@Override
public void onNext(T t) {
if (done) {
return;
}
actual.onNext(mapper.apply(t)); // 3
}
@Override
public void onError(Throwable t) {
if (done) {
return;
}
done = true;
actual.onError(t); // 4
}
@Override
public void onComplete() {
if (done) {
return;
}
done = true;
actual.onComplete(); // 5
}
@Override
public void request(long n) {
this.subscriptionOfUpstream.request(n); // 6
}
@Override
public void cancel() {
this.subscriptionOfUpstream.cancel(); // 7
}
}
- 拿到来自上游的
Subscription。 - 回调下游的
onSubscribe,将自身作为Subscription传递过去 - 收到上游发出的数据后,将其用
mapper进行转换,然后发给下游 - 将上游的错误信号原样发给下游
- 将上游的完成信号原样发给下游
- 将下游的请求传递给上游
- 将下游的取消操作传递给上游
从这个对源码的模仿,可以体会到,当有多个操作符串成 “链” 的时候:
- 向下:数据和信号(
onSubscribe、onNext、onError、onComplete)是通过每一个操作符向下传递的,传递的过程中进行相应的操作处理。 - 向上:有一个自下而上的 “订阅链”,这个订阅链可以用来传递
request,因此背压(backpressure)可以实现从下游向上游传递。
这一节最开头的那一段代码执行过程如下:

LambdaSubscriber
subscribe 方法有几个不同的变种:
subscribe(Consumer<? super T> consumer)
subscribe(@Nullable Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer)
subscribe(@Nullable Consumer<? super T> consumer,
@Nullable Consumer<? super Throwable> errorConsumer,
@Nullable Runnable completeConsumer)
subscribe(@Nullable Consumer<? super T> consumer,
@Nullable Consumer<? super Throwable> errorConsumer,
@Nullable Runnable completeConsumer,
@Nullable Consumer<? super Subscription> subscriptionConsumer)
用起来很方便,但响应式流规范中只定义了一个订阅方法 subscribe(Subscriber subscriber)。实际上,这几个方法最终都是调用的 subscribe(LambdaSubscriber subscriber),并通过 LambdaSubscriber 实现了对不同个数参数的组装。如图所示:

因此,flux.subscribe(System.out::println, System.err::println);
是调用的 flux.subscribe(new LambdaSubscriber(System.out::println, System.err::println, null, null));
🕳🕳🕳
在使用 Reactor 的开发过程中,很容易因为对于操作符的不熟悉,使得程序没有按照预期执行。 而有些预期之外的行为,并不会对整体流程造成什么影响,但是在线上环境中,它们就像是一个个 “不定时炸弹”。所以,尽可能深入地熟悉你使用的操作符,是很有必要的。
SwitchIfEmpty 总是执行
示例
首先准备一个 switchIfEmpty 时执行的方法
public Mono<Integer> emptyBackup() {
System.out.println("switchIfEmpty 执行");
return Mono.just(5);
}
Mono.just(1)
.filter(i -> i == 2)
.switchIfEmpty(emptyBackup())
.doOnNext(i -> System.out.println("onNext: " + i))
.subscribe();
输出:
switchIfEmpty 执行
onNext: 5
这段代码是没什么问题的,因为 filter 使得元素必须为 2 才能通过,而发布者只发出了一个值为 1 的元素值,执行到 switchIfEmpty 时数据流已经为空,便切换到 emptyBackup,后续的消费者执行时输出元素为 5。
我们稍微修改一下代码
Mono.just(1)
.filter(i -> i == 1)
.switchIfEmpty(emptyBackup())
.doOnNext(i -> System.out.println("onNext: " + i))
.subscribe();
把 filter 中的为 2 时才通过改为 1。
输出:
switchIfEmpty 执行
onNext: 1
奇怪,switchIfEmpty 应该不满足才对,后续输出也为 1,而不是 emptyBackup 里面的 5。但它确实执行了。
我们再修改一下代码
Mono.just(1)
.filter(i -> i == 1)
.switchIfEmpty(emptyBackup())
.doOnNext(i -> System.out.println("onNext: " + i));
输出:
switchIfEmpty 执行
这次,我们去掉了 subscribe,总所周知,数据流在订阅之前什么都不会发生。但 switchIfEmpty 仍然执行了!说明它是在装配时期就执行了。
为什么
也许这并不是关于 Reactor 的问题,而是 Java 语言本身以及它如何解析参数的问题。我们试着把上面的代码用命令式编程的方式拆开:
Mono<Integer> just = Mono.just(1);
Mono<Integer> filter = just.filter(i -> i == 1);
Mono<Integer> emptyBackup = emptyBackup();
Mono<Integer> switchIfEmpty = filter.switchIfEmpty(emptyBackup);
Mono<Integer> doOnNext = switchIfEmpty.doOnNext(i -> System.out.println("onNext: " + i));
可以看到,在我们装配 Mono 类型的数据时,emptyBackup 已经被触发了。
解决办法
在之前介绍操作符的时候有提到过,我们可以使用 Mono.defer,让它被请求时才会触发。
Mono.just(1)
.filter(i -> i == 1)
.switchIfEmpty(Mono.defer(() -> emptyBackup()))
.doOnNext(i -> System.out.println("onNext: " + i))
.subscribe();
输出:
onNext: 1
参考资料
100% 弄明白 5 种 IO 模型
响应式 Spring 的道法术器(Spring WebFlux 快速上手 + 全面介绍)
Reactor 3 参考文档
Mono(reactor-core 3.4.24)
map vs flatMap in reactor
Difference between Mono/Flux.fromCallable and Mono.defer
Mono switchIfEmpty() is always called
How to handle errors in Reactive Spring webflux
Reactor Repeat vs Retry | Vinsguru
Project Reactor - Using repeat and repeatWhen Examples
Reactor Hot Publisher vs Cold Publisher | Vinsguru
Backpressure Mechanism in Spring WebFlux
Backpressure in Project reactor - Reactive Programming | Jstobigdata
Reactor LimitRate Example | Vinsguru