
前言
有同事反馈 ApiEs 集群的 fielddata 占用过高

我的心情 be like:

fielddata 是个啥
Elasticsearch 的 fielddata 是用于聚合和排序文本类型字段的机制。它将字段数据加载到内存中,提供更灵活的查询和聚合操作。但需要注意 fielddata 可能占用大量内存,严重时会导致整个集群不可用。
排查过程
Day 1
先在 Es 中查询各个索引的 fielddata 占用情况
indices: 查看集群中所有 index 的详细信息
GET _cat/indices?v&h=index,fielddata.memory_size&s=fielddata.memory_size:desc
- GET _cat/indices:获取索引相关的信息
- ?v:verbose 返回详细的输出信息,包括表头信息
- &h:header 指定返回结果中所需的字段信息
- &s:sort 按特定字段对结果进行排序
也可使用简称
GET _cat/indices?v&h=i,fm&s=fm:desc
结果:
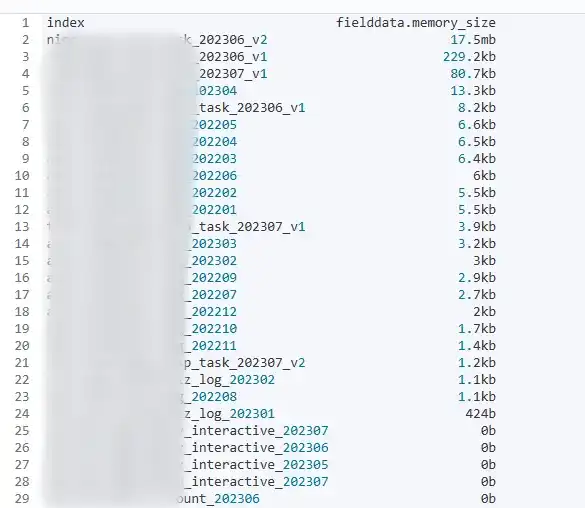
发现并没有特别异常的情况,考虑到可能是被清理了。
联想到最近新上的查询计费索引的业务,可能是计费导出接口引起的。 于是现场提交了一个较大的导出任务,持续观察 fielddata 占用情况

那再观察观察
Day 2

早上一来,又出现了。必须得好好排查一下
首先在官方文档里面寻找解决方案
如何处理 fielddata 内存使用率高问题 - 阿里云帮助中心
从中可以看到一些常见的场景和关键信息
- Elasticsearch 官方文档 中指出禁止对_id 进行聚合、排序和脚本操作
- fielddata 会占用大量的堆内存,并且堆内存占用是永久的
根据文档一一排查
…
获取占用 fielddata 内存占用高的字段,分析和业务的哪类查询相关。
GET _cat/fielddata?v&s=size:desc
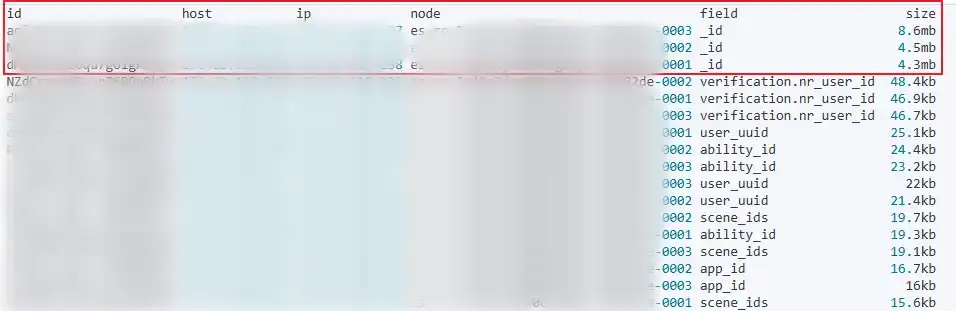
确认是使用了_id 进行聚合、排序和脚本操作引起的
接下来是定位异常的语句
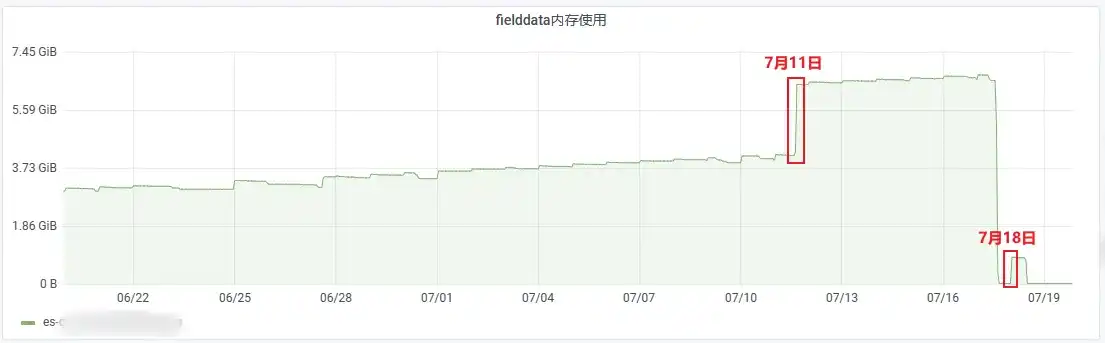
对近 30 天 fielddata 的使用情况排查,发现两个明显的异常节点,7 月 11 日和 7 月 18 日,针对这两个时间段进行日志查询

由于日志查询仅支持查询近 7 天的数据,只能选择 7 月 18 日的时间段

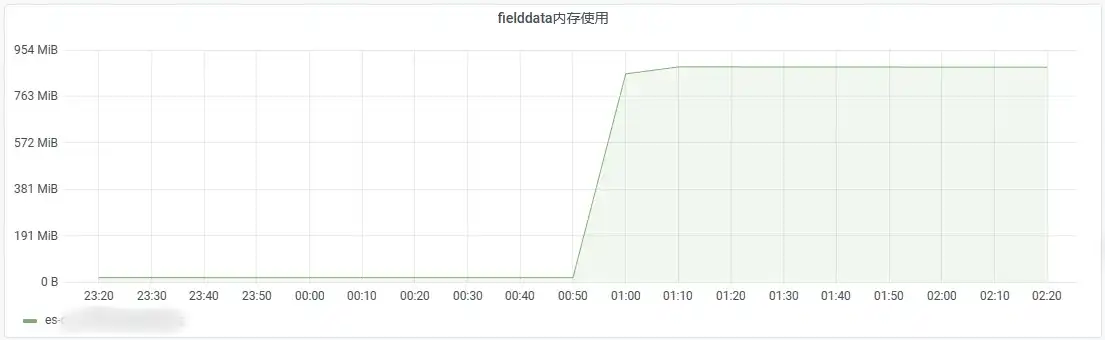
占用陡增时间段在 00:50 至 01:10 之间
uri: api_custom_biz_log
排查该段时间计费日志索引的查询语句
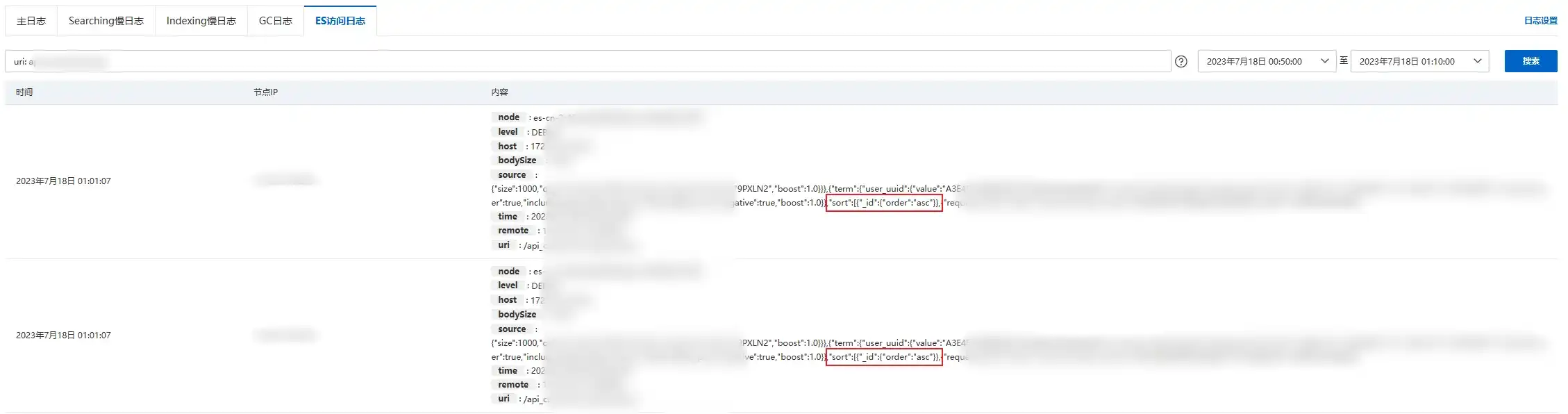
发现了使用 _id 排序的语句
精简后部分语句
{
"size": 1000,
"query": {
"bool": {
"filter": [
{
"term": {
"api_id": {
"value": "XXXXXX",
"boost": 1.0
}
}
}
]
}
},
"sort": [
{
"_id": {
"order": "asc"
}
}
]
}
通过查询语句找到对应的项目和平台,定位到代码处,反馈给负责人进行修改。
解决方案

_id 取自 request_id,字段中有保存并且是 keyword 类型

将 _id 替换为 request_id
总结
- 先从阿里云官方文档中寻找解决方案
- 借助性能监控,定位到异常发生的时间段,缩小排查范围
参考资料
一文带你彻底弄懂 ES 中的 doc_values 和 fielddata
白话 Elasticsearch51 - 深入聚合数据分析之 text field 聚合以及 fielddata 原理